2022-02-01 OLLI Bottleneck
Dear Howard,
I’ve been thinking about how difficult it is, certainly for me, to obtain and organize resources for my OLLI courses. For people like me, who like to download articles and resources, the present system is terribly inefficient and time-consuming.
To start with a very simple example, look at this web page for Claire Davidshoffer’s class.
When I saw this webpage, my impulse was to download the PDFs and store them in folders matching her titles. Then I can annotate the PDFs, highlighting passages and adding notes, to help me go back and review the articles before class.
In my file system I create folders for each of Claire’s topics and put its corresponding PDF file in it. Then I highlight and annotate it. Finally I open the enclosing folder in Obsidian, a newish technology that is making waves these days. I’d be glad to discuss it with you if it interests you. Here’s what it looks like:
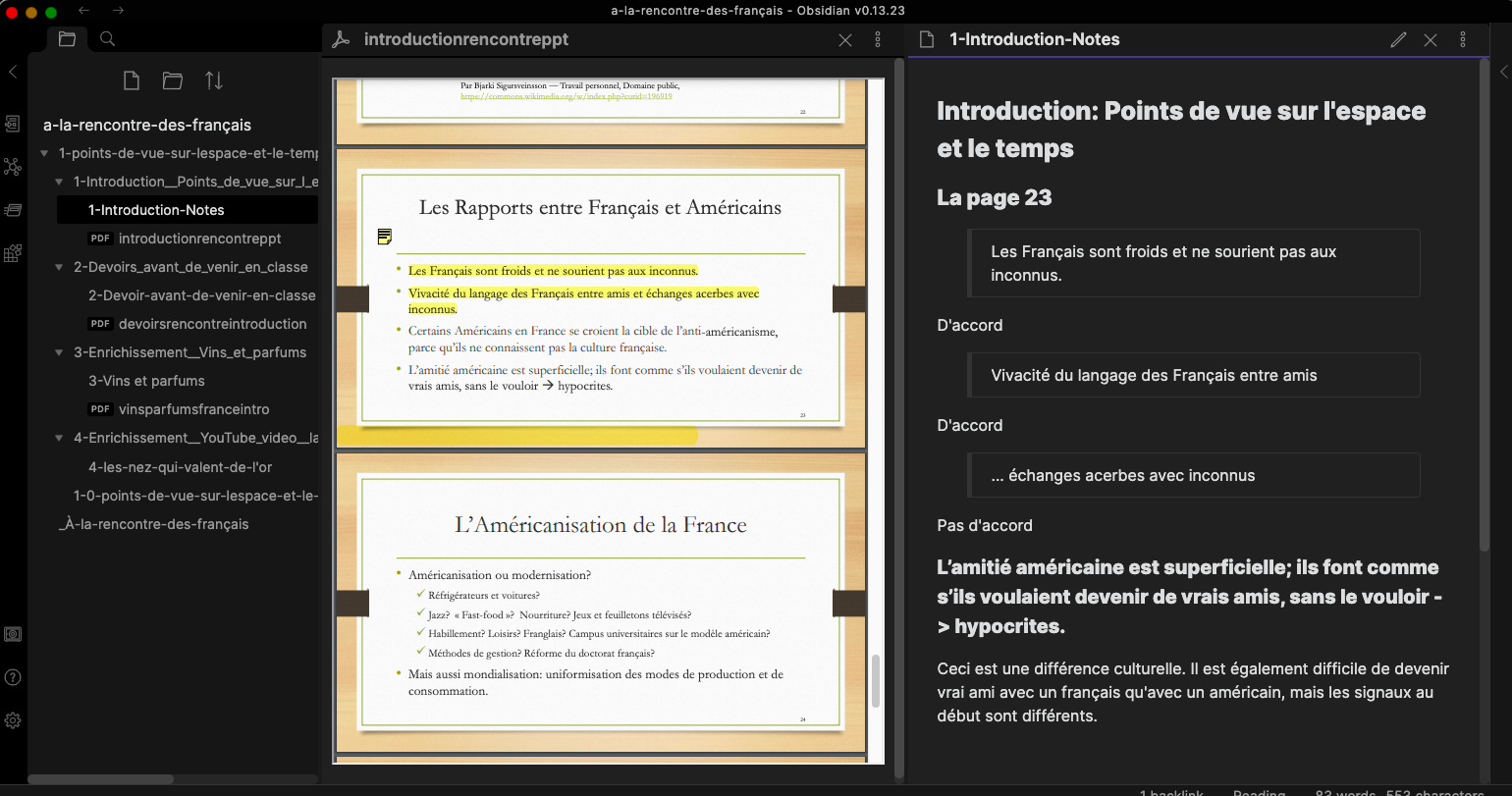
The left panel shows the folders and files, the middle one shows an annotated PDF and the right panel shows notes based on the annotations, written in markdown, a widespread technology that already underlies much of today’s web.
Back to my point: It is very tedious for me to download each PDF or other document, create folders for them, etc.
What annoys me is that the solution should be relatively simple for the instructors:
Get your documents ready.
- make folders for each topic
- place the PDF, PPT, etc. file in the folder
Zip the whole mess up and make it available for downloading.
That’s it!
Here’s an example.
I’ve zipped up the folder shown above and made it available for download here.
Or you can get it from a shell:
$ curl -O https://zabouti-east-000.s3.amazonaws.com/server/2022-02-01-OLLI-bottleneck/a-la-rencontre-des-fran%C3%A7ais.zip(If you look at the unzipped folder, you will see a file, lessons.rb, my desperate attempt to automate the downloading of data from Claire’s website. I eventually gave up.)
There are of course some problems I haven’t addressed. For example, some references are to web pages in HTML, not to PDF files. An HTML file can be downloaded, of course, as long as images, etc., are downloaded in the right place for them to find. It would be far better to turn HTML pages into PDFs for students to read.
I turned to PDFPenPro, which can convert HTML into PDF, but that costs money. Pandoc can do it, I believe, but it requires installing MacTex, which is huge. I would hope that some of Duke’s crack programmers (and that’s serious, not a crack) could whip a converter together for instructors to use to make PDFs before zipping everything up.
The reason that I’m writing to you, Howard, is that I’m having a very hard time downloading and organizing the materials in the syllabus for Intergenerational Ethics. The people who organized this course surely have these materials already downloaded and organized as they prepare the syllabus. Why make each student redo work that has already been done? (BTW I tried to parse the syllabus with a Ruby script, but the formatting was so inconsistent that I couldn’t find any useful patterns.)
I realize that lots of people are content to read articles online or they print them onto paper, etc., but some of us aren’t, and I for one am wasting a lot of time with busy work.
hth, ge